Using Insights & RCA: Complete Guide
The Insights page is where RubixKube’s intelligence shines - showing you not just WHAT failed, but WHY it failed, with complete root cause analysis, evidence, and remediation suggestions.Based on real data: This guide uses actual screenshots from a live RubixKube console monitoring 4 incident groups with 75% RCA coverage, including CrashLoop, OOMKilled, and PodPending issues.
Insights Overview
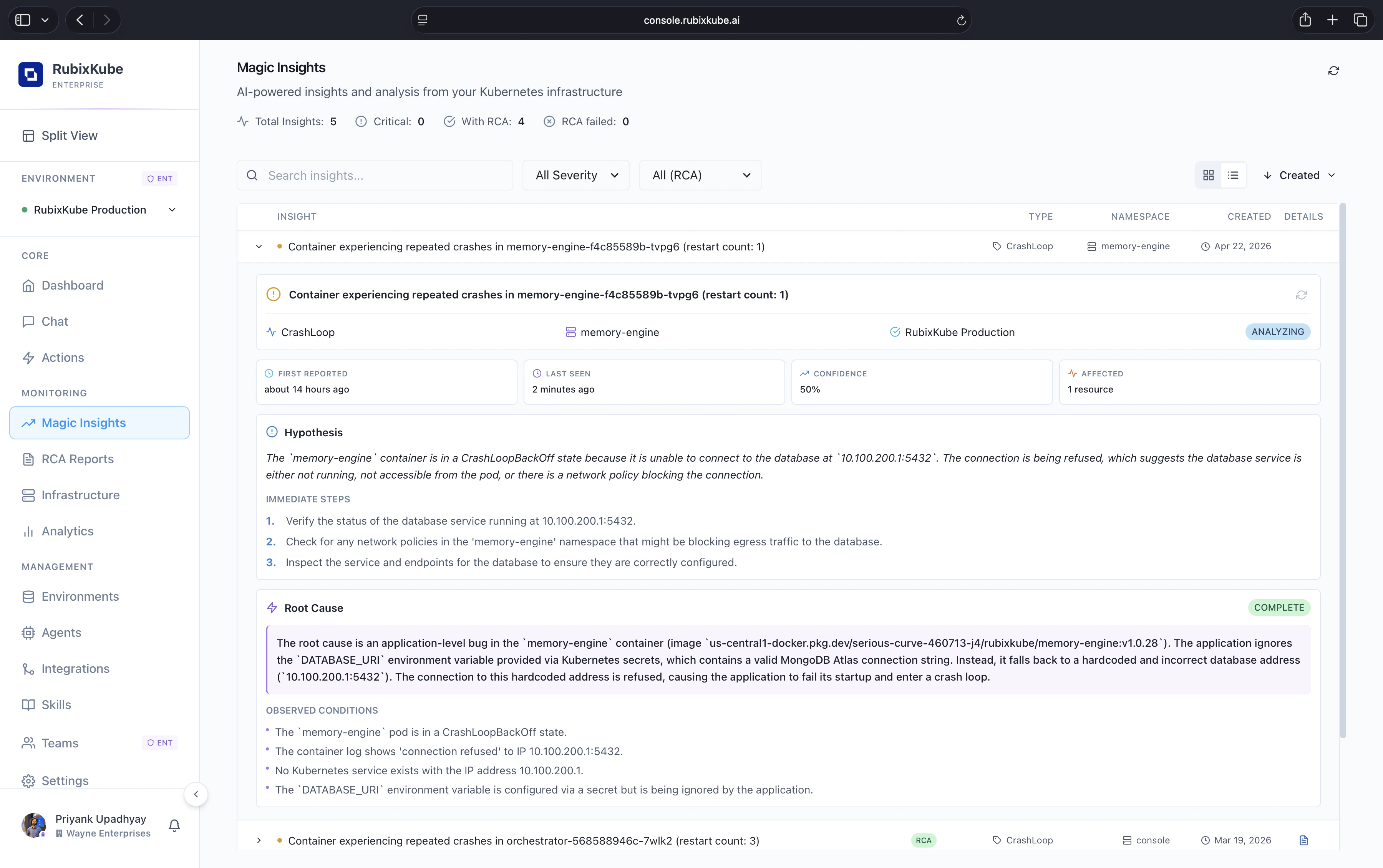
- Total Insights: every open anomaly in the selected environment.
- Critical: insights flagged as blocking.
- With RCA: insights that already have a completed root-cause report.
- RCA failed: insights where evidence did not converge on a single cause.
- Refresh data button for a manual update.
Understanding Health Metrics
Health: 75% RCA Coverage
What it means: - 75% of detected incidents have completed RCA analysis- Higher percentage = better analysis coverage
- Target: 90%+ for optimal observability
- Low coverage may indicate agent issues or complex incidents
- Tracks the intelligence level of your monitoring
Total Groups: 4
What it means: - 4 incident groups currently tracked- Groups cluster related incidents together
- Each group may contain multiple occurrences
Critical Issues: 0
What it means: - No critical-severity incidents active- Critical = system-wide failures, data loss risk
- This is your most important metric
- 1+ = Immediate response required
High Priority: 1
What it means: - 1 high-severity incident requiring attention- High = significant impact, needs prompt resolution
- Less urgent than critical, more than medium
Search and Filtering

Search Bar
Placeholder: “Search incidents, namespaces, resources…” What you can search: - Pod names (e.g., “crash-loop-demo”)- Namespaces (e.g., “rubixkube-tutorials”)
- Incident types (e.g., “OOMKilled”)
- Resource types (e.g., “Pod/”)
Filter Buttons
Available filters:
Severity Filter
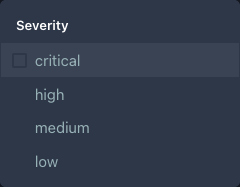
- high - Significant impact, prompt resolution needed
- medium - Moderate impact, address within hours
- low - Minor issues, informational
Incident List
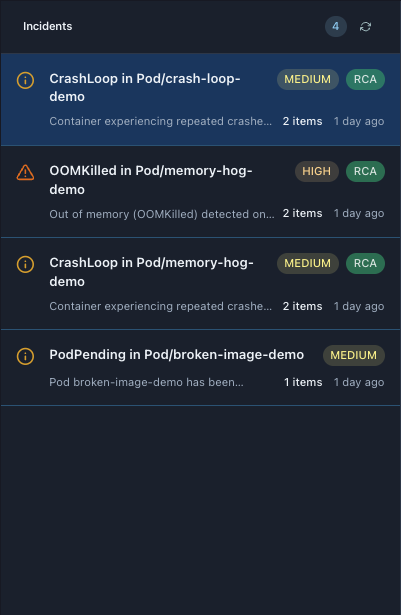
Incident Cards
From our real dashboard - 4 incidents:
1. CrashLoop in Pod/crash-loop-demo
Visual indicators: - Orange warning icon (left)- MEDIUM severity badge
- RCA badge (analysis complete)
- “2 items” - multiple occurrences
- “1 day ago” - last seen timestamp
2. OOMKilled in Pod/memory-hog-demo
Visual indicators: - Red warning triangle (left) - indicates high severity- HIGH severity badge (critical attention needed)
- RCA badge (analysis complete)
- “2 items” - multiple OOMKilled events
- “1 day ago” - last occurrence
3. CrashLoop in Pod/memory-hog-demo
Visual indicators: - Orange warning icon- MEDIUM severity badge
- RCA badge
- “2 items”
- “1 day ago”
4. PodPending in Pod/broken-image-demo
Visual indicators: - Orange warning icon- MEDIUM severity badge
- No RCA badge - analysis not complete or not available
- “1 items” - single occurrence
- “1 day ago”
Incident Detail View
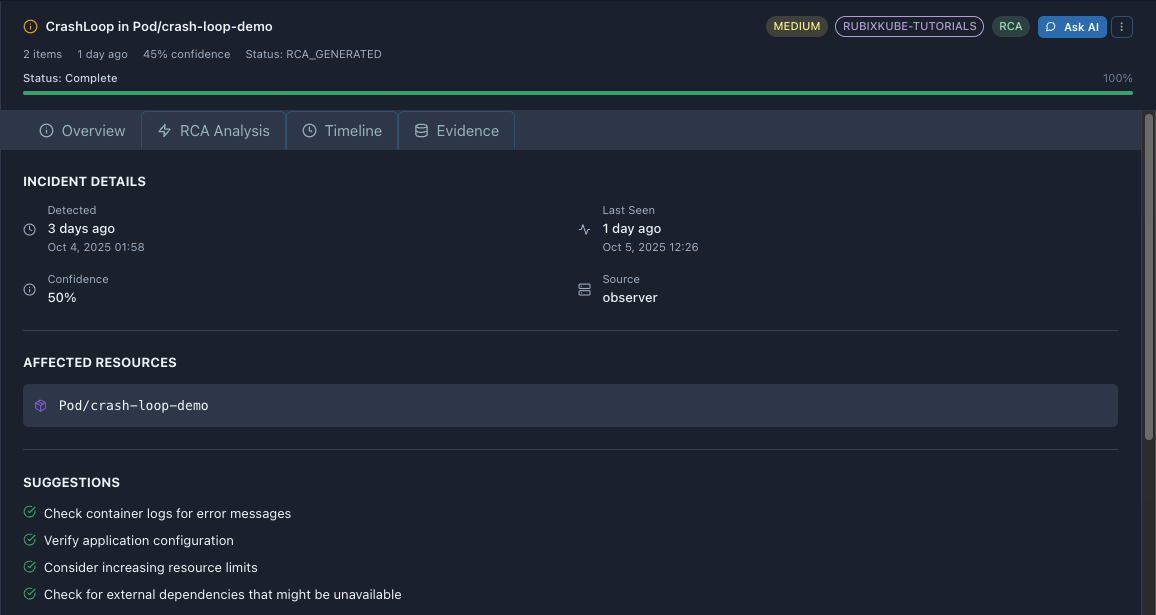
Header Section
From our example - CrashLoop in Pod/crash-loop-demo:
Title bar shows: - Warning icon- Title: CrashLoop in Pod/crash-loop-demo
- Badges:
- MEDIUM (severity)
- RUBIXKUBE-TUTORIALS (namespace)
- RCA (analysis complete)
- Ask AI button - Send to Chat for investigation
- More actions menu (three dots)
- ** 1 day ago** - last occurrence
- ** 45% confidence** - RCA confidence level
- Status: RCA_GENERATED - analysis state
- ** 100%** progress bar (green)
Overview Tab
Tab sections:
INCIDENT DETAILS
Detected: - ** Detected:** - first occurrence- Oct 4, 2025 01:58 - exact timestamp
- Oct 5, 2025 12:26 - exact timestamp
- Moderate confidence, review evidence
AFFECTED RESOURCES
Pod/crash-loop-demo - Purple cube icon indicates Kubernetes Pod- Clickable to view in Infrastructure
SUGGESTIONS
Quick remediation steps before full RCA:- Check container logs for error messages
- Verify application configuration
- Consider increasing resource limits
- Check for external dependencies that might be unavailable
SOURCE EVENTS
Original detection event: - ** Type**: CrashLoop- Pod: crash-loop-demo
- Details: “CrashLoopBackOff: container app in pod crash-loop-demo restarted 3 times”
- Namespace: rubixkube-tutorials
PROVIDE TO CHAT CONTEXT
Button at bottom - sends entire incident context to Chat interface for AI-powered investigation.RCA Analysis Tab
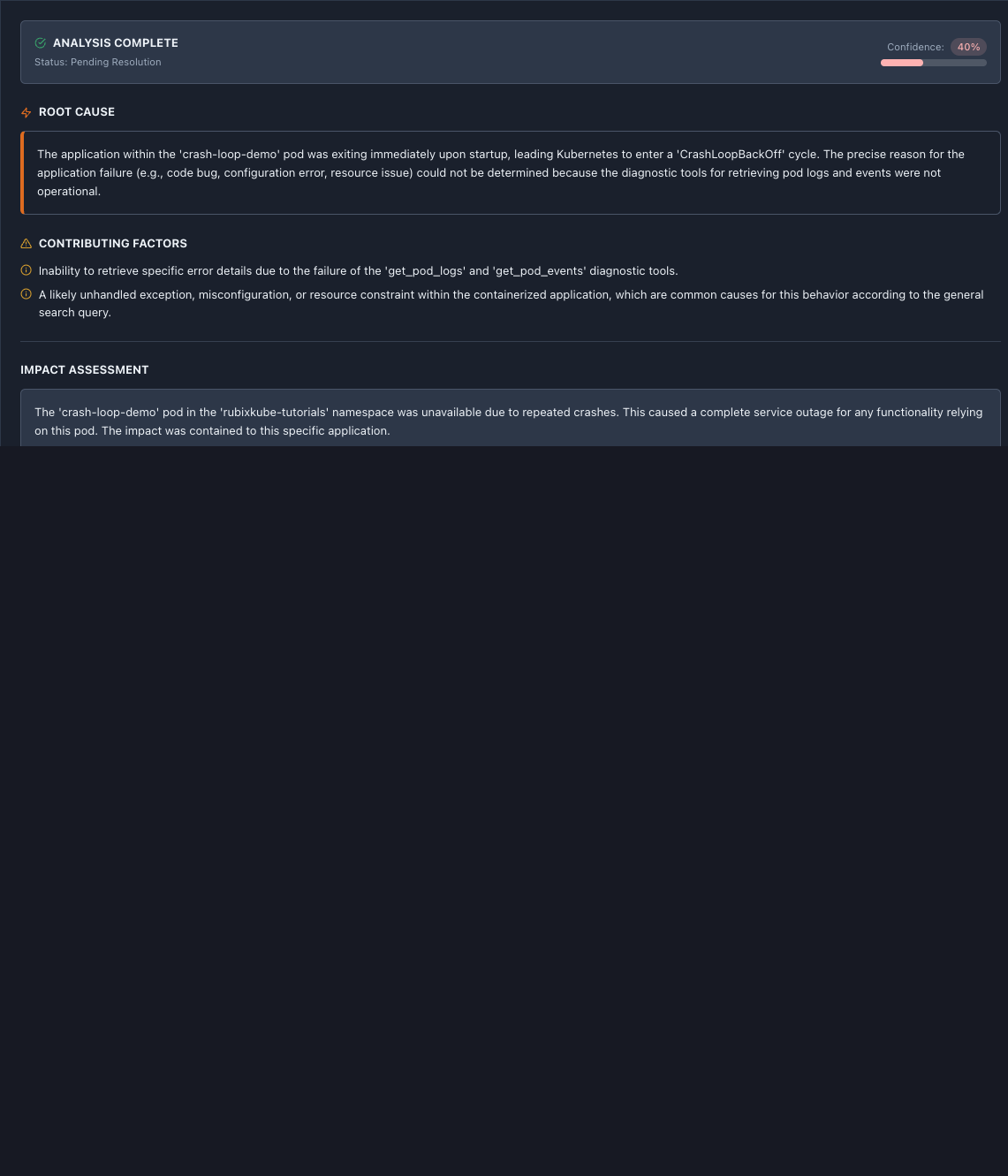
Analysis Status
ANALYSIS COMPLETE - Green checkmark icon- Status: Pending Resolution
- Confidence: 40% with progress bar
ROOT CAUSE
From our real RCA:
“The application within the ‘crash-loop-demo’ pod was exiting immediately upon startup, leading Kubernetes to enter a ‘CrashLoopBackOff’ cycle. The precise reason for the application failure (e.g., code bug, configuration error, resource issue) could not be determined because the diagnostic tools for retrieving pod logs and events were not operational.”What this tells you: - ** Primary issue**: Application exits immediately on startup
- Kubernetes response: CrashLoopBackOff protection mechanism
- Limitation: Diagnostic tools unavailable, preventing deeper analysis
- Possible causes: Code bug, config error, or resource constraint
CONTRIBUTING FACTORS
Warning triangle icon indicates factors that enabled or worsened the issue: 1.Inability to retrieve specific error details due to the failure of the ‘get_pod_logs’ and ‘get_pod_events’ diagnostic tools. 2.A likely unhandled exception, misconfiguration, or resource constraint within the containerized application, which are common causes for this behavior according to the general search query. These explain WHY the root cause occurred or why analysis was limited.IMPACT ASSESSMENT
Paragraph format explaining business impact:
“The ‘crash-loop-demo’ pod in the ‘rubixkube-tutorials’ namespace was unavailable due to repeated crashes. This caused a complete service outage for any functionality relying on this pod. The impact was contained to this specific application.”Key information: - ** Scope**: Single pod, single namespace
- Severity: Complete service outage for this pod
- Containment: No spread to other services
- Risk: Low (tutorial namespace, not production)
- Pod/crash-loop-demo (clickable resource link)
Recommended Actions
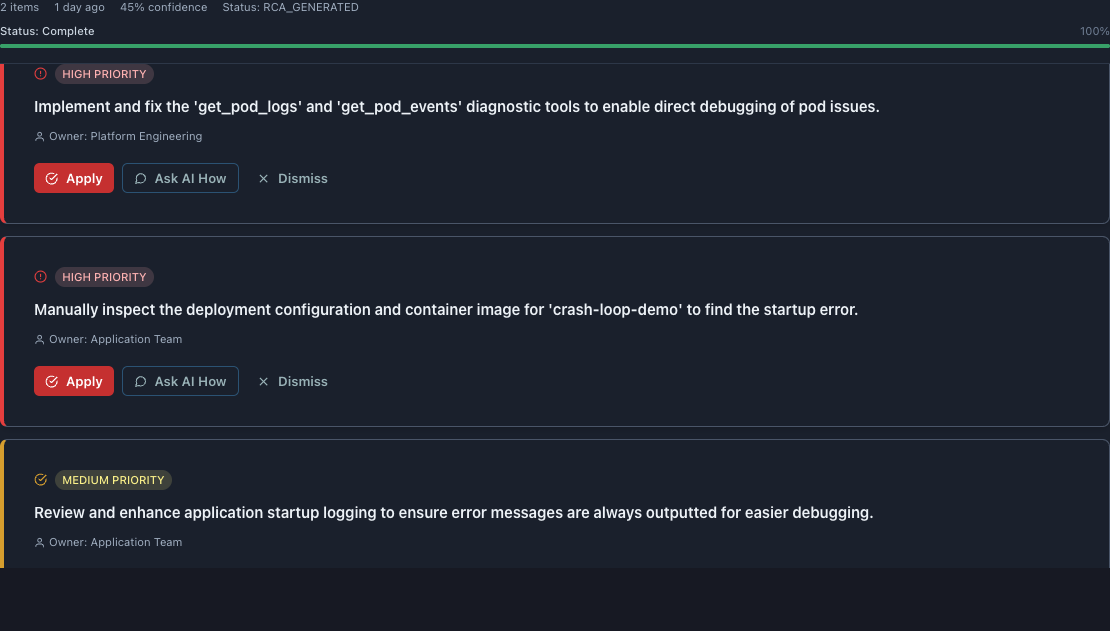
Action Card Structure
Each recommendation includes: - ** Each recommendation includes:** (HIGH PRIORITY or MEDIUM PRIORITY with colored icon)- Action description (what to do)
- Owner (who should do it - Platform Engineering, Application Team, etc.)
- Action buttons:
- Apply - Mark as implemented (red button)
- Ask AI How - Get detailed implementation steps from Chat
- Dismiss - Mark as not relevant
Real Examples from Our RCA
Recommendation #1 (HIGH PRIORITY)
Action: > “Implement and fix the ‘get_pod_logs’ and ‘get_pod_events’ diagnostic tools to enable direct debugging of pod issues.” Owner: Platform Engineering Why HIGH: - Blocks all future debugging- Affects entire RubixKube observability
- Prevents accurate RCA for all incidents
Recommendation #2 (HIGH PRIORITY)
Action: > “Manually inspect the deployment configuration and container image for ‘crash-loop-demo’ to find the startup error.” Owner: Application Team Why HIGH: - Directly addresses the failing pod- Can resolve issue immediately
- Required while diagnostic tools are unavailable
Recommendation #3 (MEDIUM PRIORITY)
Action: > “Review and enhance application startup logging to ensure error messages are always outputted for easier debugging.” Owner: Application Team Why MEDIUM: - Preventive measure- Benefits future incidents
- Not urgent for current issue
Using Action Buttons
Apply button: - Click when you’ve implemented the fix- Marks recommendation as completed
- Helps track remediation progress
- Gets step-by-step implementation guidance
- AI has full incident context
- Removes from active list
- Can undo later
Timeline Tab
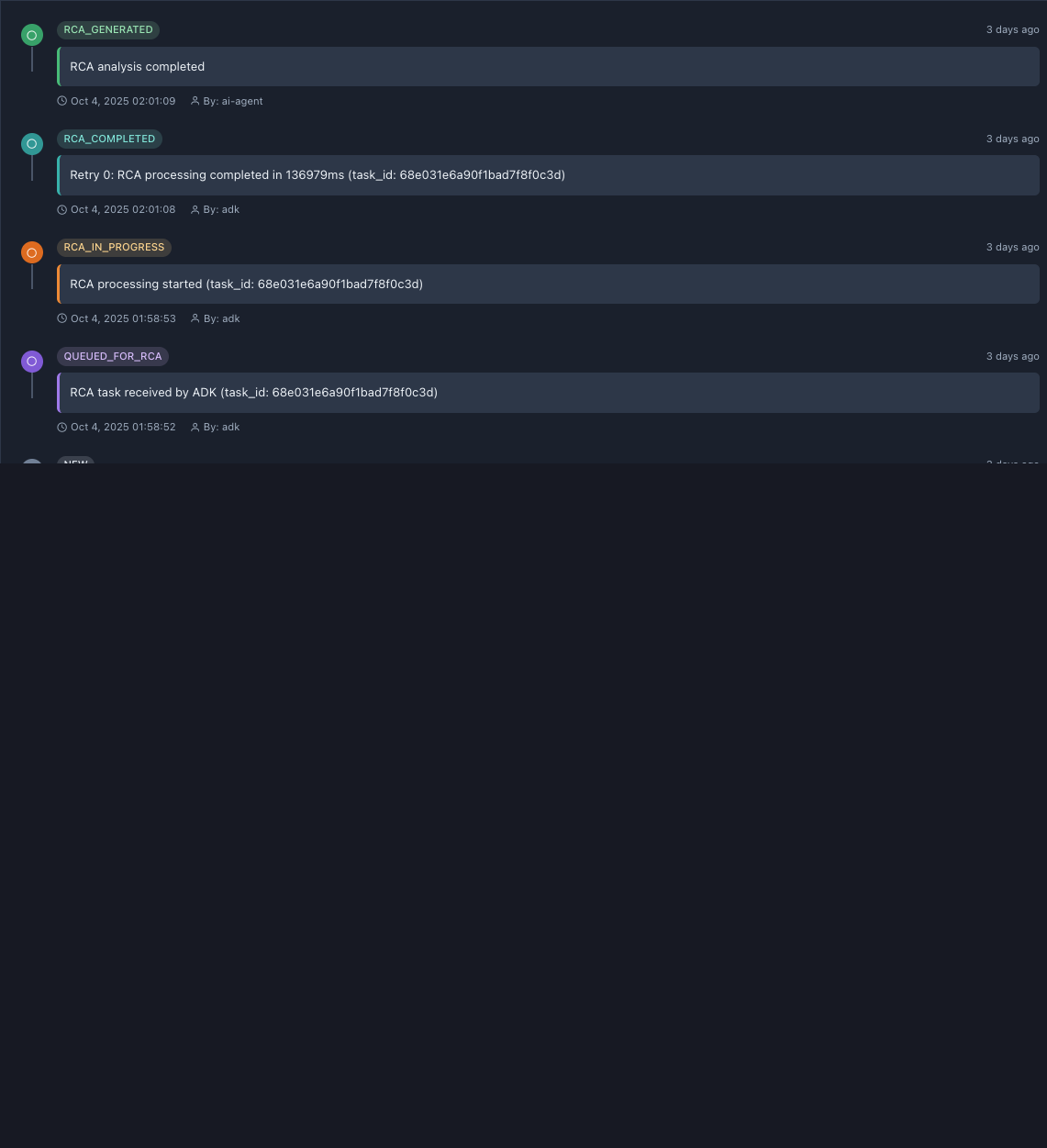
Timeline Structure
Chronological view showing:- Status changes (NEW → QUEUED → IN_PROGRESS → COMPLETED → GENERATED)
- RCA events (investigation steps)
- Timestamps (date and exact time)
- Actor (“By: observer”, “By: adk”, “By: rca-agent”)
Real Timeline from Our Incident
Latest to earliest:
1. RCA_GENERATED (3 days ago)
Event: “RCA analysis completed” Details: - Oct 4, 2025 02:01:09- By: ai-agent
2. RCA_COMPLETED (3 days ago)
Event: “Retry 0: RCA processing completed in 136979ms (task_id: 68e031e6a90f1bad7f8f0c3d)” Details: - Oct 4, 2025 02:01:08- By: adk (Analysis & Diagnosis Kit)
- Processing time: 137 seconds
3. RCA_IN_PROGRESS (3 days ago)
Event: “RCA processing started (task_id: 68e031e6a90f1bad7f8f0c3d)” Details: - Oct 4, 2025 01:58:53- By: adk
4. QUEUED_FOR_RCA (3 days ago)
Event: “RCA task received by ADK (task_id: 68e031e6a90f1bad7f8f0c3d)” Details: - Oct 4, 2025 01:58:52- By: adk
Timeline Benefits
Use timeline to: - Understand incident lifecycle- Calculate time-to-detection (NEW → QUEUED)
- Calculate time-to-analysis (QUEUED → COMPLETED)
- Debug RCA Pipeline issues
- Track investigation steps
- Correlate with external events
- Queue to In Progress: Seconds
- In Progress to Complete: 30-180 seconds
- Complete to Generated: 1-5 seconds
Evidence Tab
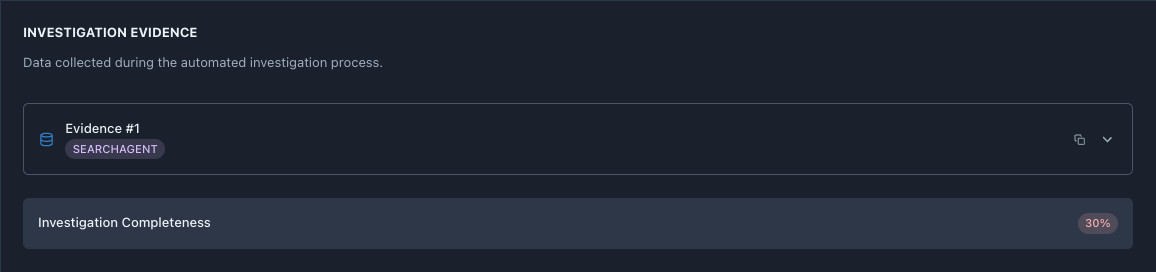
INVESTIGATION EVIDENCE
Header explains: - “Data collected during the automated investigation process”- Shows what RCA Pipeline Agent found
Evidence Items
Evidence #1
Source: SEARCHAGENT- Purple document icon
- Expandable card (click to see details)
- Copy button (top right) - copies evidence to clipboard
- Dropdown arrow - expand to read full evidence
Investigation Completeness
Bottom metric : 30%
What it means: - Investigation gathered 30% of possible evidence- Low percentage due to diagnostic tool failures (as noted in RCA)
- Higher percentage = more comprehensive analysis
- get_pod_events tool failed (would add ~30%)
- SearchAgent succeeded (contributed 30%)
- Other tools not applicable (remaining 10%)
Filtering and Workflows
Daily Review Workflow
1
Open Insights Page
Navigate to Monitoring → Insights
2
Check Health Metrics
Look at header: - RCA coverage below 80%? Investigate why
- Critical Issues > 0? Handle immediately
- High Priority increased? Review new incidents
3
Filter by HIGH Severity
Click Severity → Check “high”These need attention within hours
4
Review RCA Reports
For each HIGH incident:
- Read Root Cause
- Check Confidence level
- Review Recommended Actions
5
Apply Fixes
Click “Apply” on each action after implementingOr “Ask AI How” for guidance
6
Verify Resolution
Check incident list next dayShould move to “Resolved” status
Emergency Response Workflow
When Critical Issues > 0:
1
Immediate Filter
Severity → critical (shows only critical incidents)
2
Open Incident
Click critical incident to expand
3
Read Impact Assessment
Go to RCA Analysis tabUnderstand: What’s affected? How many users?
4
Check Recommended Actions
Scroll to actions sectionStart with HIGH priority items
5
Get AI Help
Click “Ask AI How” on most urgent actionChat provides step-by-step resolution
6
Execute and Verify
Implement fixes, monitor for resolutionMark actions as Applied when done
Troubleshooting Workflow
When RCA confidence is low (below 50%):
1
Check Evidence Tab
See what data was collectedLook for Investigation Completeness %
2
Review Timeline
Check if RCA completed successfullyLook for errors or warnings
3
Manual Investigation
If tools failed, investigate manually:
4
Use Chat
Click “Provide to Chat Context”Ask Chat to help interpret evidence
5
Feed Back to RubixKube
Contact support with findingsHelps improve future RCA accuracy
Understanding RCA Confidence Levels
From our example: 40-50% confidence
- Indicates uncertainty due to diagnostic tool failures
- Recommendations still valuable but require validation
- Manual inspection recommended before implementing
Incident Lifecycle States
State Diagram
State Definitions
NEW - Incident just detected by Observer- No RCA initiated yet
- Usually lasts: Seconds
- Waiting for processing slot
- Usually lasts: Seconds
- Gathering logs, events, metrics
- Usually lasts: 30-180 seconds
- Report being generated
- Usually lasts: 1-5 seconds
- Recommendations ready
- Stays until resolved
- RubixKube detected resolution
- Archived for learning
Integration with Other Features
Insights → Chat
Button: “Ask AI” or “Provide to Chat Context” What it does: - Sends full incident context to Chat- Includes RCA, evidence, timeline
- Chat can answer follow-up questions
Insights → Dashboard
From Dashboard Activity Feed → Click event → Opens in Insights Use case: - You see “OOMKilled” in Dashboard feed- Click to see full RCA
- Opens Insights with incident expanded
Insights → Memory Engine
Automatic integration: - Every resolved incident stored- Root causes saved to knowledge base
- Resolution patterns learned
- Speeds up future RCA
Best Practices
1. Review Insights Daily
1. Review Insights Daily
Morning routine:
- Open Insights page
- Check RCA coverage (target: 80%+)
- Filter by HIGH severity
- Review new incidents since yesterday
- Apply recommended actions
2. Triage by Severity
2. Triage by Severity
Priority order:
critical (red badge)- Drop everything, resolve immediately
- System-wide impact
- Data loss risk
- Resolve within hours
- Significant user impact
- Service degradation
- Resolve within 1-2 days
- Moderate impact
- Workarounds exist
- Resolve next sprint
- Minimal impact
- Informational
3. Trust High-Confidence RCA
3. Trust High-Confidence RCA
When confidence is 70%+:
- Implement recommendations directly
- No need for extensive validation
- RubixKube has solid evidence
When confidence is below 70%:
- Review Evidence tab carefully
- Cross-check with manual investigation
- Use “Ask AI How” for guidance
- Validate before implementing
- Due to diagnostic tool failures
- Manual verification needed
- Still provides valuable direction
4. Use Filters Strategically
4. Use Filters Strategically
Common filter combinations:
Production-only incidents: - Namespace: production- Severity: high, critical
- Sort: Newest
- Issue Type: CrashLoop, OOMKilled
- Only show incidents with RCA badge
5. Document Resolutions
5. Document Resolutions
After fixing an incident:
- Click “Apply” on each implemented recommendation
- Add notes in “More actions” menu (if available)
- Take screenshot of RCA for postmortem
- Share learnings with team
- Helps Memory Engine learn faster
- Creates audit trail
- Prevents repeated incidents
6. Leverage Chat Integration
6. Leverage Chat Integration
Don’t investigate alone:
For every incident: - Click “Ask AI” button- Chat has full context already
- Ask for explanations, steps, similar incidents
Quick Reference
Insights Page Elements
Keyboard Shortcuts
While on Insights page:R- Refresh dataF- Focus search bar1-4- Jump to first 4 incidentsTab- Navigate between tabs (Overview, RCA, Timeline, Evidence)Esc- Close expanded incident
Common Scenarios
Scenario 1: New OOMKilled Incident
What you see: - HIGH severity badge- “OOMKilled in Pod/memory-hog-demo”
- RCA badge present
What to do:
- Click incident to expand
- Go to RCA Analysis tab
- Read Root Cause (memory limit too low)
- Check Recommended Actions
- Click “Ask AI How” on “Increase memory limit” action
- Implement suggested limit (e.g., increase from 50Mi to 150Mi)
- Click “Apply” when done
- Monitor for resolution
Scenario 2: Low RCA Confidence
What you see: - Incident with 40% confidence- “Status: RCA_GENERATED” but low certainty
What to do:
- Click Evidence tab
- Check Investigation Completeness (30%)
- See which tools failed (e.g., get_pod_logs)
- Perform manual investigation:
- Click “Ask AI” with manual findings
- Chat combines RCA + your data for better diagnosis
Scenario 3: Incident Without RCA
What you see: - “PodPending in Pod/broken-image-demo”- No RCA badge
- Only shows Suggestions (not full RCA)
- RCA failed (check Timeline for errors)
- Incident type doesn’t trigger RCA
- RCA Pipeline agent offline
What to do:
- Check Timeline tab for RCA status
- If “QUEUED_FOR_RCA” but no progress:
- RCA Pipeline may be stuck
- Go to Agents page, check RCA Pipeline Agent
- If no RCA triggered:
- Use Suggestions section for generic fixes
- Click “Ask AI” for Chat investigation
- Manual investigation:
Look for ImagePullBackOff errors
Scenario 4: Multiple Related Incidents
What you see: - “CrashLoop in Pod/memory-hog-demo” (MEDIUM)- “OOMKilled in Pod/memory-hog-demo” (HIGH)
- Same pod, different incident types
- OOM is root cause
- CrashLoop is symptom
What to do:
- Open HIGH severity incident first (OOMKilled)
- Read RCA (memory limit too low)
- Fix memory limit
- Both incidents should resolve together
- Mark both as related in notes
Troubleshooting Insights Issues
Insights page not loading
Symptoms: Spinner forever, “Loading insights…” never completes Causes: - Backend API connection issue- RCA Pipeline not responding
- Database query timeout
Solutions:
- Hard refresh: Cmd+Shift+R (Mac) or Ctrl+Shift+R (Windows)
- Check Dashboard → Agents → Verify RCA Pipeline is active
- Check browser console for errors
- Try different browser
- Contact support if persists
RCA not generating
Symptoms: Incidents stuck in “QUEUED_FOR_RCA” for >5 minutes Causes: - RCA Pipeline Agent offline- Task queue full
- Resource constraints
Solutions:
- Go to Agents page
- Check RCA Pipeline Agent status
- If degraded, restart:
- Check Timeline tab for error messages
- Verify cluster has resources for RCA workload
Low RCA coverage (below 60%)
Symptoms: “Health: 55% RCA coverage” in header Causes: - Many incidents without RCA- RCA failures
- Complex incidents taking longer
Solutions:
- Filter by Status: Active, no RCA badge
- Check those incidents’ Timeline tabs for RCA failures
- Verify diagnostic tools working (get_pod_logs, get_pod_events)
- Check RCA Pipeline Agent logs:
- May need to tune RCA timeout settings in Settings
Evidence completeness always low
Symptoms: Investigation Completeness consistently 30-40% Causes: - Diagnostic tools failing- Permission issues
- Missing integrations
Solutions:
- Check which tools are failing (Evidence tab shows source)
- Verify RubixKube has proper RBAC permissions:
- Check integration connections in Settings → Integrations
- Review RubixKube Observer Agent logs for errors
What You Learned
Health Metrics
- 75% RCA coverage
- 4 total incident groups
- 0 critical, 1 high priority
- Daily monitoring targets
Incident Structure
- Severity levels (critical, high, medium, low)
- Incident groups and items
- Status lifecycle (NEW → RESOLVED)
- RCA badges and completion
RCA Analysis
- Root Cause identification
- Contributing Factors analysis
- Impact Assessment scope
- Confidence levels explained
Recommendations
- Prioritized actions (HIGH/MEDIUM)
- Owner assignments
- Apply/Ask AI How/Dismiss buttons
- Remediation tracking
Timeline View
- Chronological event progression
- RCA processing states
- Investigation duration
- Actor attribution
Evidence Collection
- Investigation completeness percentage
- Data sources (SearchAgent, logs, events)
- Diagnostic tool status
- Copy and share evidence
Filtering
- Search by name/namespace/type
- Severity, Issue Type, Namespace, Status
- Multiple selection support
- Clear filters button
Workflows
- Daily review routine
- Emergency response steps
- Troubleshooting approach
- Integration with Chat
Next Steps
Back to Dashboard
Monitor overall system health and active incidents
Use Chat for Investigation
Ask AI about incidents with full RCA context
View Infrastructure
See affected resources in topology view
Check Agent Status
Verify RCA Pipeline and Observer agents are healthy
Related Documentation
Agent Mesh Concepts
Learn how RCA Pipeline generates analysis
What is SRI?
Understand Site Reliability Intelligence philosophy
Memory Engine
How RubixKube learns from past incidents
Guardrails
Safety measures and confidence thresholds
Need Help?
Contact Support
Email: connect@rubixkube.ai
Please include your Tenant ID (Settings → Organization), timestamp, and screenshots.
Please include your Tenant ID (Settings → Organization), timestamp, and screenshots.
Troubleshooting Guide
Step-by-step fixes for common issues across Dashboard, Insights, Agents, and more.
FAQ
Answers to common questions about setup, RCA, agents, and docs.
Docs Navigation
Browse all guides to learn workflows and best practices.
Feedback
Found an issue with this guide or have suggestions? -Email : connect@rubixkube.ai -Subject : “Insights Guide Feedback”Last updated: October 6, 2025 Guide version: 2.0 Based on RubixKube Console v1.0