AI is shipping your product. RubixKube keeps it alive.
RubixKube is the Reliability Layer for the AI era. An AI-native mesh of agents that watches your infrastructure continuously, diagnoses root cause when something breaks, and keeps systems alive while your team builds. Think of it as a second brain for your infrastructure: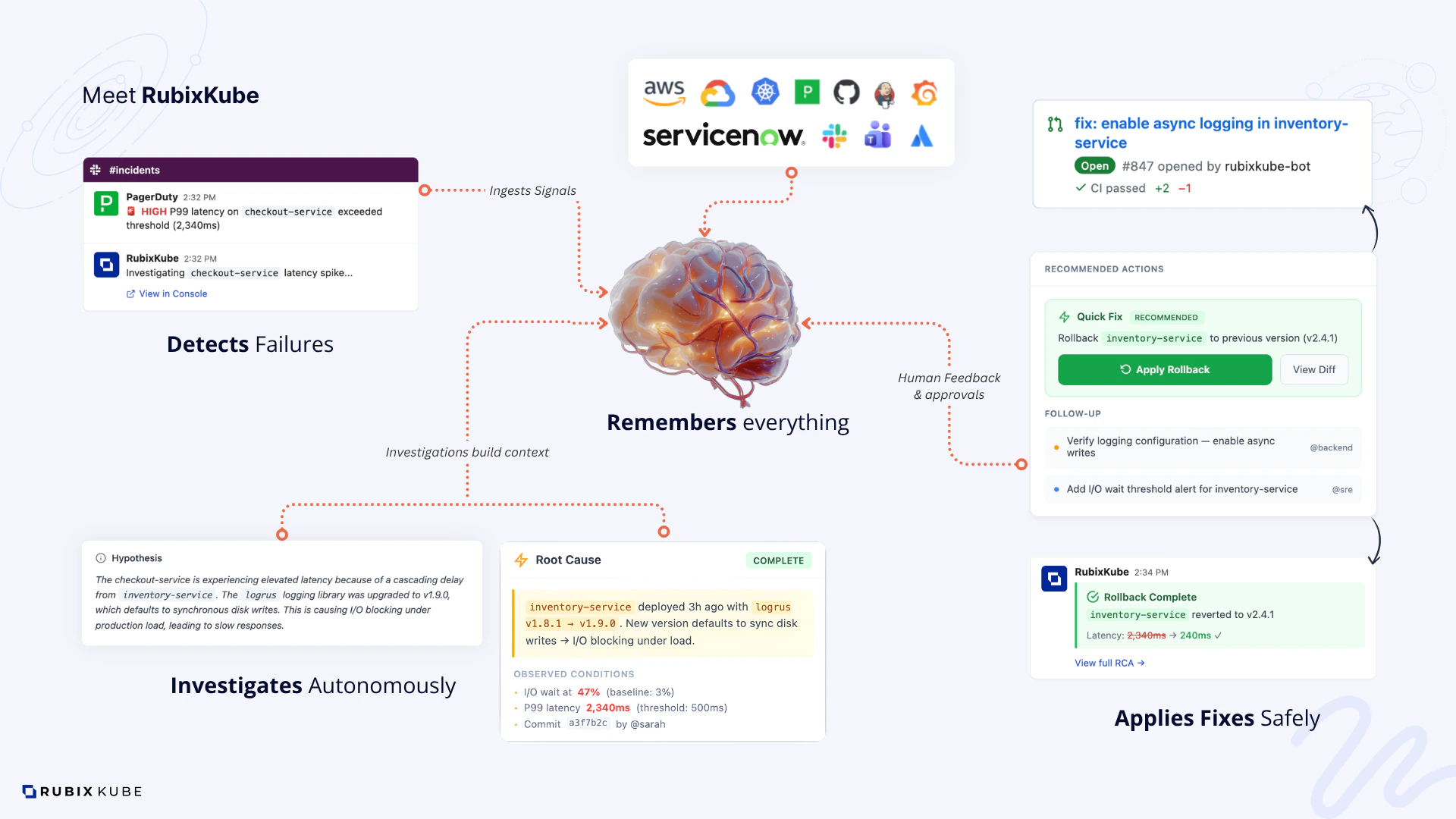
- Observes and understands your systems like a seasoned SRE
- Diagnoses issues with evidence, and shows you the blast radius
- Proposes or applies safe fixes, inside guardrails you control
- Connects every failure to real business impact
Who is RubixKube for?
SREs and platform teams
Cut MTTU from hours to minutes. Keep the on-call rotation sane.
DevOps engineers
Fewer false alerts, more real answers. Spend time building, not grepping logs.
Engineering leaders
Reliability becomes a metric you can actually report on. Revenue stays protected.
What production teams are seeing
2.8 min MTTU
Mean time to understand each issue, measured across twelve production teams.
21x faster
Than manual investigation, with a full evidence trail on every answer.
98% detection
Of material issues, paired with a 90% drop in alert noise.
Curious about the MTTU story? Read Stop optimizing for MTTR, the real bottleneck is MTTU on the blog.
How RubixKube works
RubixKube runs a mesh of specialised AI agents that each own a piece of the reliability workflow: observation, memory, root cause analysis, safe action. They share one knowledge graph of your infrastructure, so every incident makes the next one easier to solve.1
Observe
Map every service, node, and edge across your environments. Learn what normal looks like.
2
Plan
When something drifts, gather logs, metrics, events, and recent changes. Correlate them into a causal chain.
3
Execute
Recommend or apply the right fix, within guardrails you control. Blast radius is calculated before anything runs.
4
Learn
Every incident, correction, and conversation updates the Memory Engine. Your system gets sharper every week.
Read the OPEL loop origin story for the long-form explanation.
A system that learns your stack
The loop runs on every incident. The interesting part is what happens between incidents. Most tools see your infrastructure for the first time, every time. RubixKube remembers. Every signal, session, and resolution builds a deeper model of your system, one that compounds over time and belongs entirely to you.Day one
Topology mapped. Every service, node, and edge, automatically.
Week one
Dependencies understood. Upstream and downstream relationships known.
Month one
Causality emerging. Failure patterns surface before they fire.
Always
Yours, entirely. A model no other tool has, built only by being there.
What environments are supported?
RubixKube is environment-agnostic. One workspace can mix any of the following:Kubernetes
EKS, GKE, AKS, KIND, and bare metal clusters on v1.24 or later. Installs via
kubectl apply.AWS
Account-level observation across EC2, RDS, Lambda, S3, ELB, CloudTrail, and CloudWatch.
GCP
Project-level observation across GCE, GKE, Cloud SQL, Cloud Run, Cloud Storage, and Cloud Functions.
Linux VMs
Any modern Linux host, cloud or on premise. CPU, memory, disk, process, and network signals.
Azure workloads running on AKS are covered through the Kubernetes path. Subscription-level Azure observation (App Service, Azure VMs, managed data) is on the roadmap.
Root cause, not just the symptom
Every anomaly RubixKube opens carries a full investigation: observed conditions, causal chain, and recommended actions. An answer, with evidence. Not just an alert.Magic Insights
Every anomaly we have opened, with a hypothesis, immediate steps, and a completed root cause when the evidence converges.
RCA Reports
Evidence-linked postmortems. Every claim cites the log, metric, or event that supports it.
Autonomous, not reckless
RubixKube watches, analyses, and recommends. Your team decides what to do. Nothing changes in your environment without explicit approval, and every action is scoped by Guardian policies and audited end to end.Safety and Guardrails
The full safety model: least privilege, approvals, audits, and policy.
The point of all this
Not a faster tool. A smarter system. And one that is entirely yours.Every incident you resolve without RubixKube is context it never learns from. Every one you resolve with it makes the next one easier.
Where to go next
Quickstart
The ten-minute path from zero to your first investigation.
Connect your environment
Install steps for every supported environment.
Core concepts
Site Reliability Intelligence, the Agent Mesh, and the Memory Engine, from first principles.
Tutorials
Hands-on scenarios you can run against a real environment.
Common questions
Do I need an existing observability stack?
Do I need an existing observability stack?
No. RubixKube brings its own observation layer. If you already run Prometheus, Datadog, New Relic, or similar, custom integrations let RubixKube read those signals too.
Does RubixKube need privileged cluster access?
Does RubixKube need privileged cluster access?
The Observer runs with read-only permissions by default. Any action that could change state requires an approval step, and every action is scoped by Guardian policies. See Safety and Guardrails.
How much does the Observer cost to run?
How much does the Observer cost to run?
Typically around 255Mi RAM and under 10 millicores of CPU for the in-cluster Observer and Kubernetes MCP server combined. All heavier agents run in RubixKube Cloud, so your cluster stays light.
Can I try it without a real cluster?
Can I try it without a real cluster?
Yes. The Kubernetes quickstart supports KIND, so you can run the whole stack on a laptop.
Open source documentation
These docs are open source. If you spot a gap, an unclear section, or an error, the fastest fix is a pull request.Contributing guide
How to propose edits, report issues, and run the docs locally.
GitHub repository
Source for every page you are reading.